#0 Auto Scaling Groups(ASG) - 정책을 알고가자
Dynamic Scaling Polices(동적 스케일링 정책)의 세 가지 종류에 대해 알아보자
☑️ Target Tracking Scaling(대상 추적 스케일링) : 가장 단순하고 설정이 쉬운 정책
예) ASG CPU라는 지표에 대상 값을 지정한다고 할 때 ASG 전반에 걸쳐 40%라고 할 때에 CPU가 너무 높으면 ASG가 인스턴스를 추가하게 하면 되고 CPU가 너무 낮으면 ASG가 인스턴스를 종료시키는 것
☑️ Simple / Step Scaling(단계 스케일링) : 위의 것보다 조금 더 복잡한 스케일링
예) CloudWatch Alarm가 CPU가 70%이상이라 트리거되었으니 2개의 유닛을 추가하라고 할 때 혹은 Alarm이 30%미만이기 때문에 트리거되어 유닛을 제거
=> 이렇게 하면 규칙을 직접 설정해야 해서 조금 더 복잡해지지만 오토 스케일링 그룹의 스케일링 방식을 좀 더 면밀히 제어할 수 있게끔 해준다.
☑️ Scheduled Actions(예약된 작업)
예) 특정 시간대에 사용량이 크게 증가할 것임을 알고 있을 때, 미리 설정해놓는 것
+) Scheduled Actions <-> Predictive Scaling(예측 스케일링)
예측 스케일링은 예약된 작업과 반대되는데 이는 지속적으로 미래의 로드를 예측해서 스케일링 일정을 미리 설정하는 것이다.

=> 즉, AWS가 기존의 로드를 분석한 뒤에 그 자료에 기반해 예측된 로드를 생성하고 스케일링 행동을 자동으로 미리 설정해서 로드를 감당하는 데에 필요한 인스턴스의 양을 예측하는 것
이런 방식은 로드에 매주, 혹은 매일 반복되는 패턴이 있는 경우 특히 알맞을 것이다..!
#1Auto Scaling Groups(ASG) - 적합한 지표를 알고가자
ASG 스케일링에 적합한 지표로는 CPUUtilization과 RequestCountTarget이 있다.
✅ CPUUtilization : 인스턴스의 CPU 사용률을 나타낸다
이 지표를 사용하면 ASG의 인스턴스가 CPU를 얼마나 사용하고 있는지 모니터링하고, CPU 사용률이 특정 임계값을 초과하거나 미만일 때 스케일링을 트리거할 수 있다
예) CPU 사용률이 80%를 초과하면 인스턴스를 추가하고, 20% 미만이면 인스턴스를 줄이는 식으로 설정할 수 있다
✅ RequestCountTarget : 일정 기간 동안의 요청 수를 기준으로 스케일링을 결정한다
주로 애플리케이션 로드 밸런서와 함께 사용되고 초당 요청 수(RPS, Requests Per Second)나 분당 요청 수(RPM, Requests Per Minute) 등을 기준으로 스케일링을 설정한다
예) 초당 요청 수가 1000을 초과하면 인스턴스를 추가하고, 500 미만이면 인스턴스를 줄이는 식으로 설정할 수 있다
요약 및 결론💁♂️ :
CPUUtilization은 CPU 사용률이 기준
RequestCountTarget은 요청 수를 기준
CPUUtilization은 CPU 부하가 중요한 경우에 사용
RequestCountTarget은 요청 수가 중요한 경우에 사용
CPUUtilization은 인스턴스의 CPU 사용률에 따라 스케일링
RequestCountTarget은 로드 밸런서의 요청 수에 따라 스케일링
어쨌거나 EC2 인스턴스 당 요청의 수가 안정적이고 포트 당 네트워크 요청이 오버로드되지 않게 하기 위한 지표이고 형태는 다음과 같다.
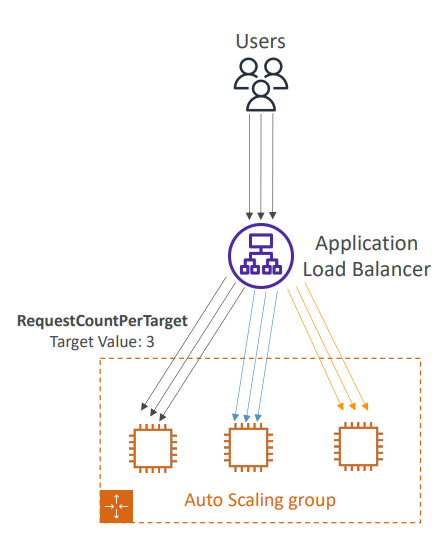
예를 들어 대상당 최대 3개의 요청을 원한다고 하면 ASG가 무슨 일이 있어도 각 EC2 인스턴스가 3개의 요청에만 응답하게끔 하는 것이다. (물론 현실에서는 천 개 요청 정도로 설정)
Average Network In/Out(평균 네트워크 인/아웃)의 경우에는 만약 애플리케이션이 많은 양의 네트워크 인/아웃을 받는 경우, 가령 EC2를 통해 비디오 파일을 업로드/다운로드한다면 EC2가 어느 정도 네트워크 인을 허용하는지를 결정하는 제한이 있는 것이다.
=> 따라서 이런 종류의 지표를 사용해서 스케일 인/아웃을 할 수 있고 CloudWatch를 사용해서 게시한 사용자 지정 지표를 사용해서도 스케일링이 가능하다.
#2 알아두면 좋은 것들 - Spot Fleet support, Lifecycle Hooks
☑️ Spot Fleet support(스팟 플릿 지원) : 스팟과 온디맨드 인스턴스를 조합해 ASG에 사용할 수 있는 것
☑️ Lifecycle Hooks(수명 주기 후크) : 인스턴스가 종료되기 전 작업을 수행할 수 있는 것
예를 들어 인스턴스가 서비스되기 전, 인스턴스를 정리하거나 로그 추출, 특별 상태 확인 들을 할 수 있는 것
+) AMI 업그레이드의 2가지 방법 알아보기
내부의 시작 템플릿, 혹은 ASG의 시작 구성을 업데이트 하는 것이고 이후에 2가지로 방법이 나뉜다.
1. EC2 인스턴스를 수동으로 종료 -> 그리고 확인을 통해 롤링 업데이트를 자동화
2. 오토 스케일링의 'EC2 Instance Refresh(EC2 인스턴스 새로고침)'을 사용하여 인스턴스 종료
ASG의 인스턴스를 종료하게 되면 새로운 인스턴스가 나타나고 기본으로 새로운 AMI를 가지게 된다.
=> 왜냐하면 ASG는 새로운 '시작 템플릿'이나 '시작 구성'을 사용하도록 되어 있기 때문
#3 오토 스케일링의 인스턴스 새로고침(Instance Refresh)
그러면 이 인스턴스 새로고침이라는 기능을 한 번 살펴보자
(이때 목표는 ASG의 가장 최신 시작 템플릿으로부터 EC2 인스턴스를 재생성 하는 것)
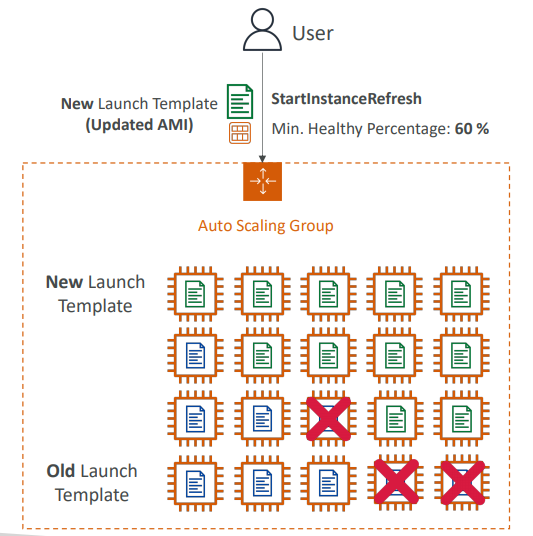
예를 들어 이렇게 ASG가 있고 기존의 시작 템플릿을 사용한 많은 EC2 인스턴스가 있는 경우 업데이트된 AMI를 가진 새로운 시작 템플릿을 ASG로 업로드하게 되면 StartInstanceRefresh API를 사용하게 된다.
=> 그러면 최소 정상 상태 인스턴스의 퍼센트를 지정해 모든 인스턴스들이 한 번에 파괴되지 않게끔 할 수 있다.
예) 60%의 인스턴스는 언제나 정상 상태여야 할 것을 지정하면 ASG는 기본적으로 기존 인스턴스를 유지하고 인스턴스 일부만 종료한 뒤 새로운 시작 템플릿을 이용해 새로운 인스턴스를 생성해 모든 인스턴스들을 새로운 시작 템플릿을 가진 인스턴스로 순차적 업데이트한다.
인스턴스의 사용 준비가 완료된 다음 기존의 인스턴스를 종료하는 워밍업 시간(warm-up time) 또한 지정이 가능하다!
'AWS' 카테고리의 다른 글
| Auto Scaling(오토 스케일링)에 관해 좀 더 자세히 알아보기 (2) (0) | 2024.06.13 |
|---|---|
| Identity Federation (1) | 2024.06.08 |
| Security Token Service(STS) (0) | 2024.05.29 |
| IAM Roles와 Resource Based Policies 차이점, 그리고 IAM Permission Boundaries에 대해 (0) | 2024.05.01 |
| IAM Policies의 JSON 문서 살펴보기 (1) | 2024.05.01 |