데이터 구조에 따라 저장하고자 한다면 AWS 데이터베이스를 이용하게 될텐데 이때, 구조를 통해서 효과적인 쿼리와 데이터 검색을 위한 인덱스를 구축할 수 있다. 그리고 데이터셋 간의 관계도 정의할 수 있다.
#0 AWS Database에 들어가기 전.. - RDS는? 📥
RDS는 관계형 데이터 베이스를 위해 존재하는데 다시 말하면 SQL을 쿼리 언어로 사용하는 데이터 베이스를 위한 관계형 데이터 베이스이다. 그리고 이걸 이용하면 AWS의 관리를 받는 데이터 베이스를 클라우드에 생성할 수 있다.
(종류 : Postgres, MySQL, MariaDB, Oracle, Microsoft SQL Server, Aurora(AWS가 소유하는 데이터 베이스) 등..)
왜 EC2에 직접 데이터베이스를 배포하는 대신 RDS를 사용하는 걸까? 🤸
- RDS는 관리형 데이터 베이스 서비스라서
- 데이터 베이스 공급이 자동으로 이루어진다. (OS 패치는 AWS에서 해줄 것이다)
- 지속적인 백업과 특정 시점으로의 복원도 가능할 것이다.
- 데이터 베이스의 상태를 확인하기 위한 모니터링 대시보드가 있다.
- 읽기 전용 복제본을 통해 부하를 분산시키고 읽기 속도를 개선시킬 수 있다.
- 다중 가용영역(Multi-AZ) 설치를 통해 가용성 영역 다운에 대비하여 재해 복구 계획을 마련할 수 있다.
- 마지막으로 업그레이드를 위한 점검창 설치가 제공되고 수직확장과 수평확장이 모두 가능하다..!
...
하지만 RDS로 하지 못하는 유일한 것이 있다.
데이터베이스 관리는 AWS가 다 하기 때문에 SSH 유틸리티를 이용하여 데이터 베이스의 상황을 들여다보는 것은 불가능하다.
어쨌거나 위에 정리해놓은 이점들을 아래에서 조금씩 풀어나가보려고 한다.
#1 Amazon Aurora
AWS가 만든 데이터베이스 기술. RDS와 같은 방식으로 운영되며 Aurora는 PostgreSQL과 MySQL 두 가지 데이터 베이스 기술을 지원한다. Aurora는 클라우드에 최적화를 목표로 하고 심지어 Aurora는 용량을 신경 쓸 필요가 없다.(자동으로 늘려주기 때문)
+) Amazon Aurora Serverless(아마존 오로라 서버리스) -> 선택 사항
서버리스에서는 데이터베이스 인스턴스화가 자동화되며 DB의 실제 사용 정도에 기반해서 확장이 된다. PostgreSQL과 MySQL 둘 다 데이터 베이스 엔진으로 기능할 수 있고 초마다 값이 매겨지는데다 용량을 사전에 기획 안 해도 되어서 작업량이 간헐적으로 가끔 발생하거나 예상하기 어려울 때 가장 유용하다..!

=> 고객이 Aurora에서 관리하는 Proxy Fleet(프록시 플릿)에 연결하면 Aurora는 보이지 않는 곳에서 규모를 확장하거나 축소가 필요할 때 데이터 베이스 인스턴스를 만들거나 없앤다.
#2 RDS 데이터 베이스를 배포하는 방법 ⤴️ - Read Replicas, Multi-AZ, Multi-Region
<Read Replicas> - RDS 읽기 전용 복제본을 사용하는 방식
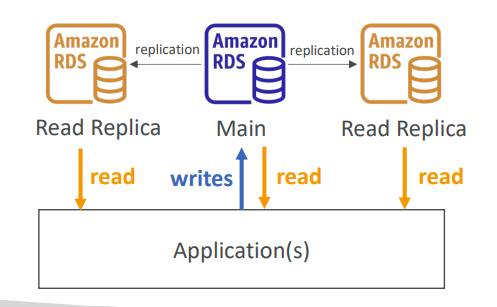
읽기 복제본을 생성하는 것으로 최대 15개의 읽기 복제본을 생성할 수 있다. 데이터 쓰기 작업의 경우, 쓰기 작업은 오직 메인 데이터 베이스에서만 이루어지므로 애플리케이션을 오직 둥앙 RDS 데이터 베이스 한 곳에만 데이터를 기록할 수 있다.
<Multi-AZ> - 다중 가용영역

AZ 운영정지와 같은 장애조치가 발생했을 떄 유용하게 쓰인다. => 충돌이 났을 때 높은 가용성을 보장
<Multi-Region> - 다중 리전

이 방법 또한 읽기 전용 복제본을 다우는데 한 region이 아닌 여러 region을 걸치게 된다. 그리고 서로 다른 region에 있는 애플리케이션도 로컬 데이터 베이스로부터 읽어들이기 때문에 지연시간이 짧다는 메리트가 있다.
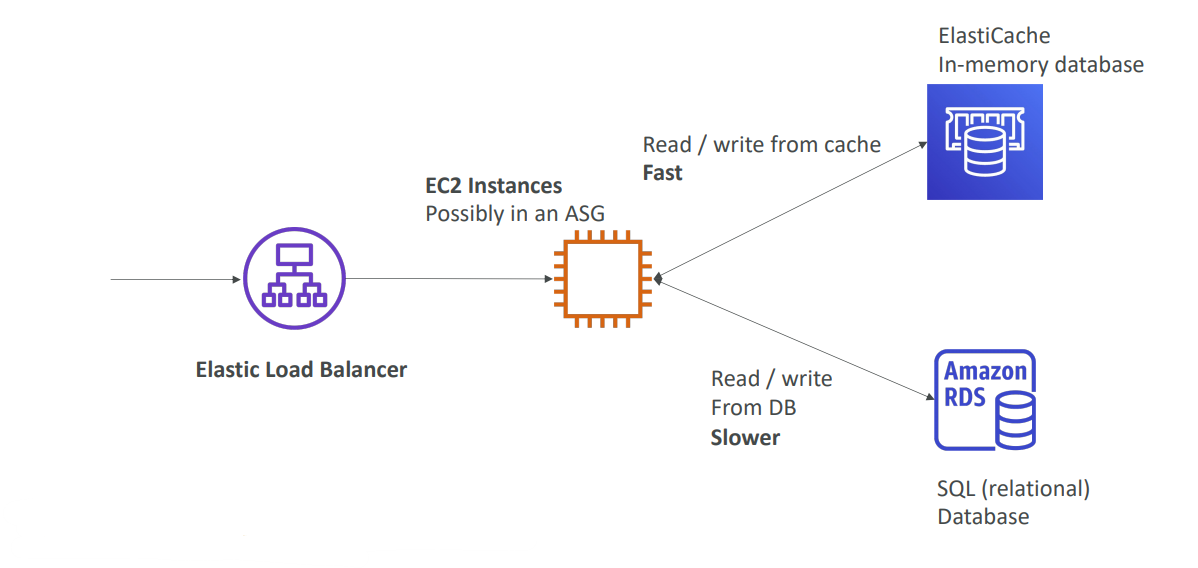
#3 Elasti Cashe(일라스티 캐시)란?
RDS를 관리형이자 관계형 데이터 베이스에서 사용했던 것처럼 일라스티 캐시를 사용해서 관리형 레디스 또는 Memcashed 데이터 베이스를 이용해볼 수 있다.
이와 같은 캐시는 높은 성능과 짧은 지연시간을 자랑하는 In-Memory(인메모리) 데이터 베이스이다.
일라스티 캐시는 읽기 집중적인 워크로드의 데이터 베이스로부터 워크로드를 줄일 때 용이하게 쓰인다. RDS 데이터 베이스에서는 많은 쿼리 자업을 수행하는데 항상 동일한 쿼리를 다루게 되면 RDS 데이터 베이스에 막대한 부하가 발생한다..!
=> 그래서 인 메모리 데이터 베이스인 일래스티 캐시를 사용하면 캐시가 직접 전동되도록 해서 데이터 베이스의 부하를 줄일 수 있고 사용을 통해 AWS가 모든 운영체제의 유지보수, 패치작업, 최적화 설정, 구성, 모니터링, 장애회복, 백업등등 담당할 수 있다.
#4 DynamoDB & DAX 🧑🤝🧑
DynamoDB란?
완전 관리형 고가용성 데이터베이스로 세개의 AZ에 걸쳐 복제본을 두고 운영된다.
비관계형 데이터베이스(NoSQL)이며 막대한 작업향도 수행할 수 있고 분산된 서버리스(serverless) 데이터 베이스이다.
=> 즉 RDS나 일래스티 캐시를 이용해서 서버에 프로비저닝할 필요 X (원래라면 인스턴스 유형에 프로비저닝이 필요하겠지만 이거는 필요가 없다)
빠르고 일관적인 성능을 가지고 있다고 하며 지연시간이 적고 보안, 인증, 관리상 IAM과 통합되어 있으며 비용이 적고 오토 스케일링 기능을 갖추고 있다.
DynamoDB에는 어떤 데이터가 저장될까? 🧐
먼저 DynamoDB는 키/값 데이터 베이스로 데이터는 다음과 같은 양상으로 저장된다.

위의 예시 그림으로 설명할 수 있다.
- 우리의 데이터에 대해 '열'을 임의로 정의할 수 있다.
- 모든 Item들은 '행'으로 저장된다.
=> 데이터 검색의 지연시간이 짧고 서버리스 데이터 베이스에 대한 액세스가 가능
DAX (= DynamoDB 전용 캐시) 📀
DynamoDB를 위한 완전 관리형 인메모리 캐시(일래스티 캐시와 달리 DynamoDB 전용 캐시이다.)
DAX를 사용하면 성능이 10배 이상 확장이 되고 보안과 확장성, 가용성 모두가 높다.
일래스티 캐시와의 또 다른 차이점은 DAX는 DynamoDB와 완전히 통합되어있어서 DynamoDB에서만 사용하나 일래스티 캐시는 다른 DB에서도 캐시 저장에 사용할 수 있다.

+) DynamoDB - Global Table (글로벌 테이블)
짧은 지연시간으로 DynamoDB테이블에 액세스할 수 있도록 하는 기능
여러 region에서 가능하다는 점이 중요하다. 해당 글로벌 테이블이 있는 모든 AWS region에서 읽기/쓰기 액세스가 가능하다는 점은 곧 액티브-액티브 복제(Active-Active replication)라는 뜻이 된다..!
=> 액티브-액티브 복제 (Active-Active replication) :
어느 region이든 직접 쓰고 해당 내용은 바로 다른 region에 복제된다는 의미
#5 RedShift - 데이터 분석과 계산하는 일에 특화 📝
RedShift는 PostgreSQL기반의 데이터 베이스로 OLTP에는 사용되지 않는다 (OLAP에 특화되어있기 때문)
- RedShift를 사용하면 데이터를 지속적으로 로드하지 않아도 된다 -> 시간 설정해서 로드 가능
- 다른 데이터 웨어 하우스들의 10배 이상의 성능을 자랑하며 '행' 기반에 반대되는 '열' 기반의 스토리지로 불려진다.
- 또한 RedShift는 MPP 엔진이라는 것을 가지고 있어서 이러한 계산들을 엄청나게 빨리 해낼 수 있다.
- 우리가 공급한 인스턴스에 따라 비용이 청구되면 조회는 SQL 인터페이스를 통해 수행된다.
AWS의 Quicksight나 Tableau와 통합되어서 쓰임 - 그래서 데이터 웨어하우스(창고)에 대시보드를 생성하고자할 때 유용
< RedShift의 기능 - RedShift Serverless >
이걸 이용하면 RedShift를 실행하면서고 데이터 웨어하우스(창고)의 크기 조정과 공급같은 것을 걱정할 필요가 없다.
분석 작업을 실행하고 데이터 창고 기반은 관리하지 않는 발상인데 그래서 편리한 기능이다.
usecase : 보고서 작성, 대시보드 애플리케이션, 실시간 분석 등등..

Amazon EMR, Amazon Athena, Amazon QuickSight, DocumentDB, Amazon Neptune, Amazon Timestream, Amazon QLDB, Amazon Managed Blockchain, AWS Glue, DMS 등 여러가지 세세한 기능들이 있으니 찾아보면 좋다.
'AWS' 카테고리의 다른 글
| AWS Global 인프라에 사용되는 서비스와 기능에 관해 (0) | 2024.03.08 |
|---|---|
| 대규모 배포 및 인프라에 관한 서비스 살펴보기 (1) | 2024.03.07 |
| S3 버킷 개념과 버킷 정책 만들어보기, S3로 웹사이트 호스팅해보기 (6) | 2024.03.05 |
| EC2 Instance Storage (0) | 2024.03.04 |
| EC2 인스턴스 생성하기, 윈도우로 SSH 실행하는 방법과 더 편한 방법 (0) | 2024.03.03 |