AWS 조금 공부해보면 알 수 있다. 기본적으로 EC2는 가용성이 좋지 않다는 것을..
EC2 인스턴스는 기본적으로 하나의 AZ에서 실행된다.
그래서 가용성이 높지가 않은데 여러 가지 방법으로 가용성을 높일 수도 있어서 정리해본다!
(요구 사항 및 하고 싶은 일의 양에 따라 상이)
#0 간단하게 가용성 높여보기
웹 서버를 가동하고 있는 공용 EC2 인스턴스가 있고 웹 서버에 액세스한다고 가정해보자.

그러려면 EC2 인스턴스에 탄력적 IP를 연결하고 사용자가 탄력적 IP를 통해 웹사이트에 곧장 액세스하게 해야한다..!
그러면 사용자는 EC2 인스턴스에서 직접 작업할 수 있고 우리는 웹 서버에서 결과를 받을 것이다.
...
이제 이 글의 의도한 바로
일이 잘못될 경우를 대비해 대기 인스턴스를 만들어
EC2 인스턴스의 가용성을 높여보겠다.

일이 잘못될 경우를 대비하려면 대비 EC2 인스턴스에 장애조치를 취해야 한다.
=> 잘못된 것을 알기 위해 CloudWatch를 모니터링 요소로 넣어주기
이미 알고 있는 이벤트에 기반해 CloudWatch Events나 경보(Alarm)을 만들어보겠다. 왜냐하면 CloudWatch Events가 있다면 인스턴스가 종료되고 있는지 확인할 수 있을 것이기 때문이다.
웹서버가 있다면 CPU가 100%까지 올라갈 경우를 대비해 CPU를 모니터링하는 CloudWatch Alarm을 설정해야겠죠
만약 CPU가 100%에 도달한다면 EC2 인스턴스에 문제가 생긴 것이고 그에 관한 경보를 발동해야 할 것이다.
(인스턴스를 모니터링하는 방법은 여러 개가 있고 요구 사항에 따라 달라지니 잘 찾아보기)
...
그 후에 경보나 CloudWatch Events에서 Lambda함수를 발동할 수 있는데 Lambda 함수를 통해 우리가 원하는 작업을 할 수 있게 한다. 지금과 같은 경우엔 예를 들어 API를 호출해 인스턴스가 실행되지 않았을 경우 실행할 수 있게끔 한다.
그 후, 대기 인스턴스에 탄력적 IP를 연결하는 API를 호출할 수도 있다. 이제 탄력적 IP가 연결되면 이 IP는 다른 인스턴스에서는 분리되는데 한 탄력적 IP는 한 인스턴스에서만 연결될 수 있기 때문이다. 다른 EC2 인스턴스는 종료되거나 사라질 것이고 새 대기 EC2 인스턴스에는 장애 조치가 취해지는 것이다.
...
하지만 사용자는 탄력적 IP를 통해 아키텍처와 소통하기 때문에 무슨 일이 일어나는지는 알 수 없다🥶
=> 다 백엔드에서 진행되기 때문
#1 Auto Scaling(오토 스케일링) 이용하기
두 가용영역에 오토 스케일링 그룹(ASG)가 있다고 치자
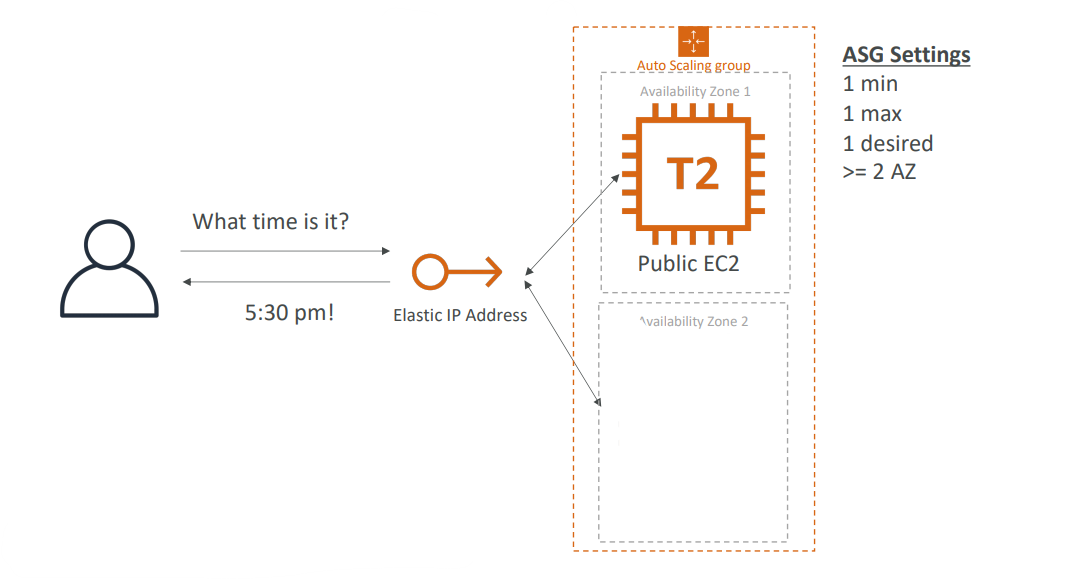
위랑 같은 개념을 적용할건데 사용자가 탄력적 IP를 통해 애플리케이션과 소통하게 만들어 조금 더 단순화하는 것이다.
...
그러려면 ASG를 어떻게 구성해야 할까?🙎♂️
제안⬇️
인스턴스의 최솟값과 최댓값을 1로 설정하고 적정 값도 1로 설정해서 두 개의 가용 영역에 지정하는 것이다.
=> 이게 무슨 뜻이냐면 EC2 인스턴스를 하나만 가져오는 것인데 그 인스턴스는 첫 번째 가용 영역에 들어가게 된다.
...
왜 이 설정을 적용해야 할까?
예를 들어 EC2 인스턴스의 사용자 데이터가 나타나게 되면 이 탄력적 IP 주소를 태그에 기반에 연결할 것이다. 이 사용자 데이터가 API 호출을 발행하고 탄력적 IP가 공용 EC2 인스턴스에 연결되는 것이다. 그러면 사용자가 웹 서버와 소통할 수 있게 된다.
...
이젠 이 인스턴스가 종료될 경우, ASG가 뭘 하는지 알아보자
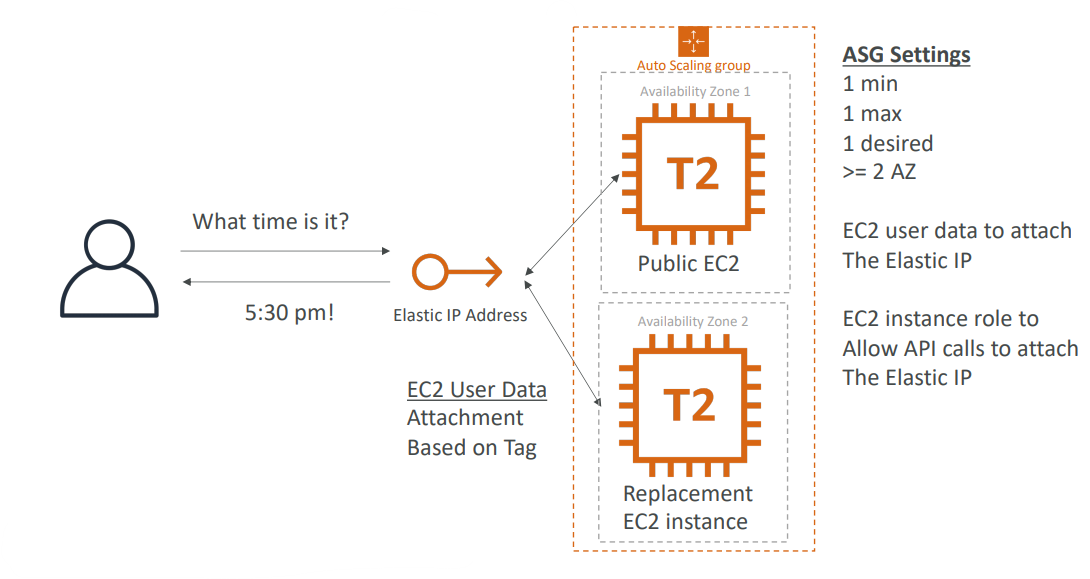
ASG는 첫 인스턴스를 종료하고 다른 가용 영역에 대체 EC2를 생성할 것이다. 그러면 첫 번째 인스턴스가 종료되고 두 번째 인스턴스가 EC2 사용자 데이터 스크립트를 실행하고 탄력적 IP를 연결할 것이다.
=> 이렇게 하면 사실상 장애 조치가 취해진다.
(이 경우에는 심지어 CloudWatch Alarm이나 Events가 필요가 없다😀)
한 인스턴스가 종료되는 것을 ASG가 보자마나 아까 설정한 대로 다른 가용 영역에 새 EC2 인스턴스를 생성할 것이다. 최소, 최대, 적정 값을 1로 설정한 이유는 ASG 전체에서 동시에 여러 개의 인스턴스를 실행할 수 없기 때문이다..!
마지막으로 EC2 인스턴스가 이 탄력적 IP 주소를 연결하기 위해 API를 직접적으로 호출할 때 해당 인스턴스가 탄력적 IP 주소를 연결하기 위해 API를 호출할 수 있는 인스턴스 역할이 있는지 확인해야 한다.
⬇️⬇️⬇️
# ASG + EBS
이제 EC2 사용자 데이터를 이용해 탄력적 IP 주소를 연결하고 API 호출이 성공할 수 있도록 EC2 인스턴스 역할을 설정을 한꺼번에 해보겠다. 이 패턴은 다른 영역으로도 확장이 가능하다.

예를 들어 EC2 인스턴스를 상태 유지하게끔 하고 EBS 볼륨을 줄 수 있다.
(좀 더 복잡해지는데..!)
위에서 다룬 바탕을 다시 정리하자면 ASG와 두 가용 영역 공용 EC2 인스턴스와 탄력적 IP가 있는 것은 다 알텐데 지금은 EC2 인스턴스에 EBS 볼륨까지 연결하려는 것이다.
EC2 인스턴스가 데이터베이스라고 할 때 이 데이터베이스를 고가용성으로 만든다고 할 때, 모든 데이터가 EBS 볼륨에 있고 EBS 볼륨은 특정 가용 영역에만 고정되어 있다.
이제는 EC2 인스턴스가 종료된다고 가정해보자.
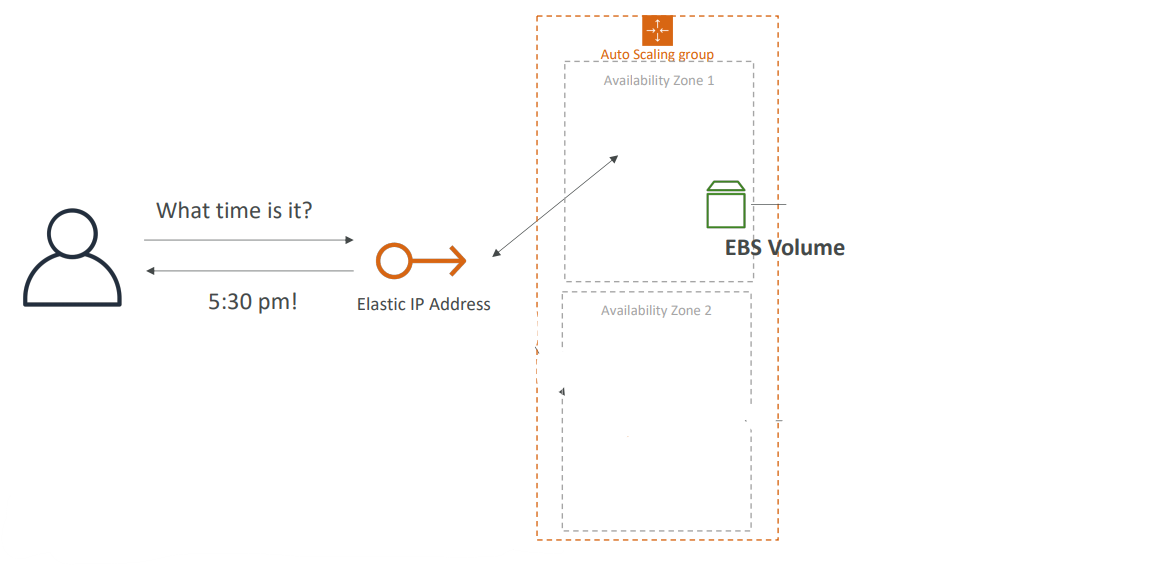
⬇️

인스턴스가 종료될 경우 ASG 수명 주기 후크(ASG Launch lifestyle hook)를 사용한다.
이 수명 주기 후크 덕분에 EBS 볼륨에서 스냅샷을 얻을 수 있는 스크립트를 생성할 수 있다.
EC2 인스턴스가 종료되자마자 스냅샷이 발동되기 때문에 EBS 볼륨에 문제가 생겼다는 것을 알 수가 있는 것이다.
이제 EBS 스냅샷을 올바르게 태그하면 ASG는 대체 EC2 인스턴스를 실행할 것이다.
(이전 설정과 같음)
이제 실행 이벤트에 수명 주기 후크를 생성하도록 ASG를 올바르게 구성함으로써 이 EBS 스냅샷에 기반에 올바른 가용 영역에 EBS 볼륨을 생성할 수 있다. 그리고 대체 EC2 인스턴스에 이걸 연결하면 EC2 사용자는 이것만 확인하고 탄력적 IP를 직접적으로 연결하면 된다. 그러려면 API호출이 제대로 됐는지 확인해야 하니 EC2 인스턴스 역할이 있어야 한다.
그림에서 보이듯이 EBS 볼륨이 스냅샷을 만들고 그 스냅샷에서 다른 가용 영역으로 복구되는지 확인하기 위해 EC2 사용자 데이터 및 수명 주기 후크를 이용했는데 이게 바로 EBS 볼륨으로 고가용성 EC2 인스턴스를 만드는 법이다.
...
이렇게 고가용성으로 만드는 방법은 가지각색인데 이런 아키텍처들의 작동 방식을 살펴보면 여러 가지 아이디어가 떠올릴 수 있을 것 같아 정리했는데 다른 분들도 제 블로그 보면서 같은 부분에서 도움을 얻으셨으면 좋겠습니다😄👍
'AWS' 카테고리의 다른 글
| IAM Roles와 Resource Based Policies 차이점, 그리고 IAM Permission Boundaries에 대해 (0) | 2024.05.01 |
|---|---|
| IAM Policies의 JSON 문서 살펴보기 (1) | 2024.05.01 |
| 솔루션에 따라 아키텍처 정리해보기 - IP 주소 차단이 필요할 때 (1) | 2024.04.26 |
| 솔루션에 따라 아키텍처 정리해보기 - SQS&Lambda와 Fan out pattern (0) | 2024.04.23 |
| VPC에 대해 조금 더 자세히 알아보자 (5) - VPC Peering, VPC Endpoint (0) | 2024.04.21 |