#0 Auto Scaling Group(ASG - 오토 스케일링 그룹)이란?🔎
웹사이트나 애플리케이션을 배포할 때, 웹사이트 방문자가 갈수록 많아지면서 로드가 바뀔 수 있는데
AWS에서 자동으로 증가한 로드에 맞춰 EC2 인스턴스를 추가(스케일 아웃 - Scale Out)하거나
감소한 로드에 맞춰 EC2 인스턴스를 제거(스케일 인 - Scale in)하는 것을 말한다.
또한 다른 특징은 아랫 글처럼 정리할 수 있다.
1. 매개변수값으로 ASG에서 실행되는 EC2 인스턴스의 최대/최소 개수를 보장한다.
2. 로드 밸런서와 페어링하는 경우 ASG에 속한 모든 EC2 인스턴스가 로드 밸런서에 연결된다.
3. 한 인스턴스가 비정상이면 종료하고 이 종료한 걸 대체할 새 EC2 인스턴스를 생성한다.
4. ASG는 무료고 EC2 인스턴스같은 생성된 하위 리소스에 대한 비용만 내면 된다.
< 로드밸런서와 ASG 조합 >
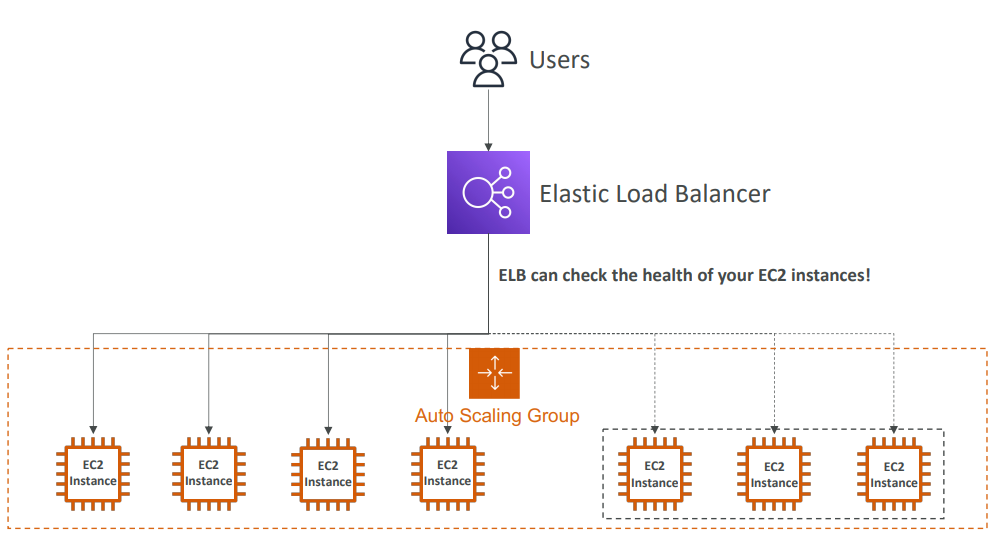
< CloudWatch와 ASG 조합 >

ClousWatch 경보를 기반으로 ASG를 스케일 인/아웃할 수 있는데
경보를 울리게 되면 스케일 아웃이 발생한다.
그러면 어떠한 항목 때문에 경보를 울릴까?🔔
지표를 통해 평균 CPU나 커스텀 지표를 지정할 수가 있는데 예를 들어 ASG 전체 CPU평균이 너무 높으면 EC2 인스턴스 추가가 필요한데 지표에 따라 경보가 울리면 ASG의 스케일링 활동을 유발하게 해준다.
=> 경보를 기반으로 스케일 인/아웃 정책을 만들어서 인스턴스 수를 늘리거나 줄일 수 있고
이 모든것들이 함께 ASG를 구성한다.
#1 Auto Scaling Group의 스케일링 정책 살펴보기 📑
<Dynamic Scaling Policies - 동적 스케일링 정책>🕺
동적 스케일링 정책은 총 3가지 유형이 있는데 아래와 같다.
- Target Tracking Scaling(대상 추적 스케일링) : 가장 단순, 설정하기 쉽다.
예를 들어 모든 EC2 인스턴스에서 ASG의 평균 CPU 사용률을 추적해서 이 수치가 40%대에 머물 수 있도록 할 때에 사용한다 => 기본 기준선을 정하고 상시적으로 가용이 가능하도록 하는 것
- Simple / Step Scaling(단순/단계 스케일링) : 조금 더 복잡하다.
전체 ASG에 대한 CPU사용률이 70%를 초과하는 경우 용량을 두 유닛 추가하도록 설정하거나 30%이하면 하나를 지우는 등 설정도 추가할 수 있다.
- Scheduled Actions(예약된 작업) : 나와있는 사용 패턴을 바탕으로 스케일링 예상하는 것
예를 들어 최소 용량을 오후 5시마다 자동으로 10까지 늘리는 등 스케일링이 필요함을 미리 알 때에 '예약한 작업'을 설정하면 된다.
<Predictive Scaling - 예측 스케일링>✍️
예측 스케일링을 통해서 AWS내에 ASG 서비스를 활용해서 지속적으로 예측을 생성할 수 있다.
=> 로드를 보고 다음 스케일링을 예측하는 것
시간에 걸쳐서 과거 로드를 분석하고 예측이 생성된다. 해당 예측을 기반으로 사전에 스케일링 작업이 예약된다.
(머신러닝을 기반으로 예측 스케일링이 나중에 미래에 더 전망이 좋은 스케일링 방법이다!)
+) CPU사용률에 관한 이야기인데 일반적으로 인스턴스에 요청이 갈 때마다 일종의 연산이 수행되어야 하니 이 과정에서 일부 CPU가 사용된다. 모든 인스턴스의 평균 CPU 사용률을 봤을 때, 이 수치가 올라가면 인스턴스가 잘 되고 있다는 의미니까 스케일링에 있어서 좋은 지표가 된다.
<Scaling Cooldown>

스케일링 작업이 끝날 때마다 인스턴스의 추가나 삭제를 막론하고 기본적으로 일정 시간동안 휴지 기간을 갖는 것이다. 휴지 기간에는 ASG가 추가 인스턴스를 실행하거나 종료할 수 없다.
=> 이는 지표를 이용해서 새로운 인스턴스가 안정화될 수 있도록 하고 어떤 새로운 지표의 양상을 살펴보기 위함이다.
이것 때문에 스케일링 작업이 발생할 때에 기본적으로 설정된 Scaling Cooldown이 있는지 확인해야 한다.
(있으면 해당 작업을 무시하기 때문에.. 아닐 경우에는 인스턴스 실행/종료 스케일링 작업을 수행하는 것이다)
즉시 사용 가능한 AMI를 이용해서 EC2 인스턴스 구성 시간을 단축하고 이를 통해 요청을 좀 더 빨리 처리하는 것이 좋다.
#2 AWS RDS(관계형 데이터 베이스 서비스)
AWS Database에 관해
데이터 구조에 따라 저장하고자 한다면 AWS 데이터베이스를 이용하게 될텐데 이때, 구조를 통해서 효과적인 쿼리와 데이터 검색을 위한 인덱스를 구축할 수 있다. 그리고 데이터셋 간의 관계도
670811.tistory.com
📢 : 이전에 블로그에 따로 데이터베이스에서 다룬 적이 있는데
여기서 더 추가된 정보를 아래에서 다루려고 합니다.
궁금하다면 윗글을 먼저 읽고 아래에 정리한 글을 읽으면 더 알기 쉽습니다.
#3 RDS Read Replicas(읽기 전용 복제본)의 사용사례 살펴보기 📖

예를 들어 평균적인 로드를 감당하고 있는 프로덕션 데이터베이스가 있다고 가정했을 때, 프로덕션 데이터베이스에서는 메인 RDS 데이터베이스 인스턴스에 대한 읽기 및 쓰기가 수행된다. 이때 새로운 팀이 와서 우리의 데이터를기반으로 몇 가지 보고와 분석을 실시하고자 한다 했을 때 reporting application을 메인 RDS 데이터베이스 인스턴스에 연결하면 오버로드가 발생하고 생산속도가 느려지는 현상을 피하기 위해 새로운 워크로드에 대한 Read Applicas(읽기 전용 복제본)을 생성해고나면 메인 RDS 데이터베이스 인스턴스와 읽기 전용 복제본 간의 비동기식 복제가 발생한다. 그 다음 reporting application이 생성한 읽기 전용 복제본에서 읽기 작업과 분석을 실행하게 되는 것이다. (production application은 전혀 영향을 받지 않는 구조이다)
그리고 당연히 읽기 전용이므로 SELECT문만 사용한다.
+) Read Applicas(읽기 전용 복제본)과 관련된 네트워킹 비용 살펴보기 💵
원래 AWS에서는 하나의 AZ에서 다른 AZ로 데이터가 이동할 때에 비용이 발생한다.
그런데 Read Applicas(읽기 전용 복제본)에서는 예외가 존재하는데 아래 그림을 보면서 같이 살펴보자
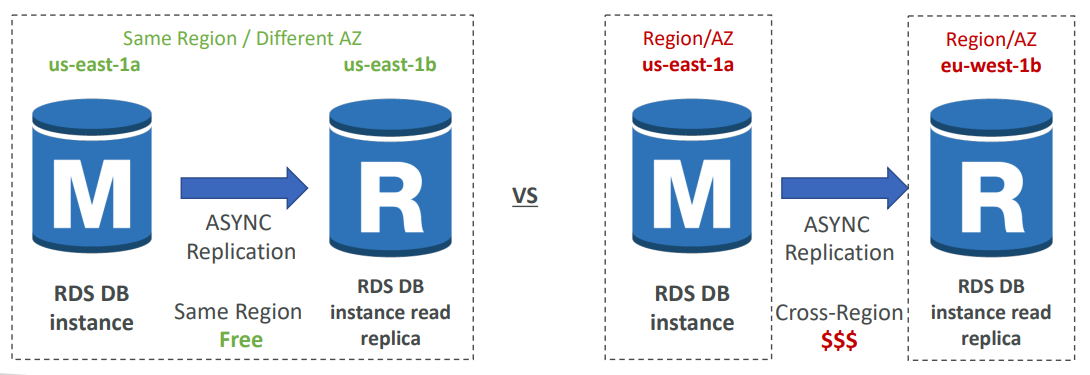
일단 왼쪽과 같이 읽기전용 복제본이 다른 AZ상이지만 동일한 region에 있을 때에는 비용이 발생하지 않는다..!
그렇지만 서로 다른 region에 복제본이 존재하는 경우에 여러 region을 넘나들어야 하기 때문에 네트워크에 대한 복제 비용이 발생한다.
#4 RDS Multi AZ - 재해 복구에 사용🛀

그림 상의 이 애플리케이션은 AZ A에서 읽기와 쓰기를 수행하는 마스터 DB 인스턴스인데 동기식으로 이를 AZ B에 standby 인스턴스로 복제한다.
마스터 데이터베이스의 모든 변화를 동기적으로 복제하는 것인데 이는 애플리케이션의 마스터에 쓰이는 변경 사항이 대기 인스턴스에도 그대로 복제된다는 것을 의미한다.
즉 하나의 DNS 이름을 갖고 애플리케이션 또한 하나의 DNS 이름으로 통신하며 마스터에 문제가 생길 때에도 standby 인스턴스에 자동으로 장애 조치가 수행된다.
...
이를 통해서 가용성을 높일 수 있기에 Multi AZ(다중 AZ)라고 불린다.
=> 다시 정리하자면 전체 AZ 또는 네트워크가 손실될 때에 대비한 장애 조치고 마스터 데이터베시으의 인스턴스나 스토리지에 장애가 발생할 때 standby 데이터베이스가 새로운 마스터가 될 수 있도록 하는 것이다.
(따로 앱에서 수동으로 조치를 취할 필요 X)
그리고 standby 데이터베이스는 단지 대기 목적 하나만 수행하기 때문에
그 누구도 읽거나 쓸 수 없고 그저 문제가 발생할 경우에 대비한 장애 조치 그 이상 그 이하도 아니다.
+) 단일 AZ에서 다중AZ로 전환이 가능할까?🔄
이 작업 자체에 다운타임이 없어서 전환할 때에 데이터베이스를 중지할 필요가 없고
데이터베이스 수정을 클릭하고 Multi AZ기능을 활성화시키기만 하면 된다.
그림을 통해 보이지 않는 곳에서 어떤 작업이 이루어지는지 알아보자.

기본 데이터베이스의 RDS가 자동으로 스냅샷을 생성한다.
(이 스냅샷은 새로운 스텐바이 데이터베이스에 복원)
스텐바이 데이터베이스가 복원되면 두 데이터베이스 간 동기화가 설정되므로
탠바이 데이터베이스가 메인 RDS 데이터베이스 내용을 모두 수용하여 다중 AZ 설정 상태가 된다.
✅짤막한 개념 정리
재해 복구를 대비해서 읽기 전용 복제본을 다중 AZ로 설정할 수 있다.
'AWS' 카테고리의 다른 글
| RDS (3) (0) | 2024.03.24 |
|---|---|
| RDS (2) - Aurora에 대해 알아보자 (0) | 2024.03.23 |
| AWS Load balancer(로드 밸런서)에 대해 조금 더 자세히 알아보자 (2) (0) | 2024.03.21 |
| AWS Load balancer(로드 밸런서)에 대해 조금 더 자세히 알아보자 (1) (0) | 2024.03.20 |
| EBS에 대해 조금 더 자세히 알아보자 (0) | 2024.03.19 |